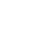清华新闻网11月15日电 近日,清华大学交叉信息研究院高阳研究组在强化学习领域中取得突破,研究组所提出的模型EfficientZero首次在雅达利(Atari)游戏数据上超过同等游戏时长的人类平均水平。EfficientZero的高效率学习能力为强化学习算法应用到现实世界场景提供了更大可能。
EfficientZero在Atari 100k(2h环境数据)基准下与其他算法结果对比
该研究成果一经公开,便在学术圈引发关注和热议,收获大量好评。另有科技方向的博主做了半小时的视频讲解此文,短短两天即有上万人次观看。
网友在Twitter上的转发以及在YouTube上的讲解视频
雅达利游戏是目前强化学习领域最常用的性能测试标准之一,它包含丰富的游戏场景,且各个游戏规则各异。在2015年,Deep Mind团队提出算法DQN,通过200M帧训练数据,在雅达利游戏上达到了人类平均水平。
然而EfficientZero达到同等水平仅仅需要DQN需求数据量的1/500。而低样本效率是限制强化学习算法应用于真实场景的障碍之一,这是因为在真实场景中,实验人员无法像在模拟场景中获取大量数据用于训练模型。这表明EfficientZero的高样本效率与高性能能够让强化学习算法更加贴近真实应用的场景,为强化学习算法能够落地提供了更大的可能性。
部分雅达利游戏展示
EfficientZero是一种基于模型的算法,基于此前的MuZero模型,这类模型一方面通过收集的数据来学习环境模型,从而能够预测环境的变化,另一方面利用所学出的模型预测未来的轨迹和所得回报,通过MCTS进行规划,从而在少量训练数据情况下能够达到较高的性能。EfficientZero提出了三点改进:时序一致性,预测阶段回报,修正目标价值。其中时序一致性的实现是通过计算机视觉领域中的对比学习算法SimSiam实现的,这使得状态转移模型所预测的下一步状态靠近真实轨迹的下一步状态,从而促进状态转移模型的学习。
研究提出,在训练过程中有些状态的回报是很难预测的,因此预测每步状态的回报会有较高的不确定性,但是预测阶段的回报相对来说更加平滑,从而减少这种不确定性。研究组通过更改目标价值函数实现离线策略价值函数的纠正。此外,EfficientZero还在部分模拟机器人控制环境DMControl中进行了实验,并取得了目前最佳性能,这也进一步表明EfficientZero在更复杂的模拟环境情形下仍然能维持高样本效率和高性能。
该成果的研究论文“用有限的数据玩转雅达利游戏”(Mastering Atari Games with Limited Data)被2021年神经信息处理系统进展大会(NeurIPS 2021)接收。该论文的第一作者为交叉信息研究院2020级博士生叶葳蕤,通讯作者为高阳助理教授。其他作者包括加美国加州大学伯克利分校教授彼得·阿贝尔(Pieter Abbeel)、交叉信息研究院2020级硕士生刘绍淮以及加州大学伯克利分校博士生塔纳德·库鲁塔赫(Thanard Kurutach)。
供稿:交叉信息研究院
编辑:李华山
审核:吕婷