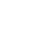清华新闻网12月11日电 随着具身机器人的场景泛化需求和数字内容创作需求,根据自然语言的场景描述,从预定义的资产集合中生成逻辑连贯且丰富的自定义3D场景布局(文本-3D场景生成)成为一项具有挑战性的任务。传统方法定义精确的规则既耗时又需要大量的艺术专业知识,并且限制了复杂和多样场景组合的表达。基于深度学习的方法,当前数据集仍然相对有限,生成结果缺乏多样性,无法完全满足艺术专家的实际需求。近期基于大语言模型的场景生成方法虽然通过语言模型提取布局先验,但在空间感知和几何精度上仍有不足,难以准确表示复杂的空间关系、建模对象姿态,并符合美学设计原则。

图1.文本-3D场景生成系统获得的高质量3D场景
为此,清华大学深圳国际研究生院曾龙副教授课题组与合作者联合攻关,研究搭建一个3D场景布局系统(图2),能在给定某个高质量的3D资产库的情况下,在文本或图像输入下即可生成自然、细致且逻辑连贯的3D场景布局。
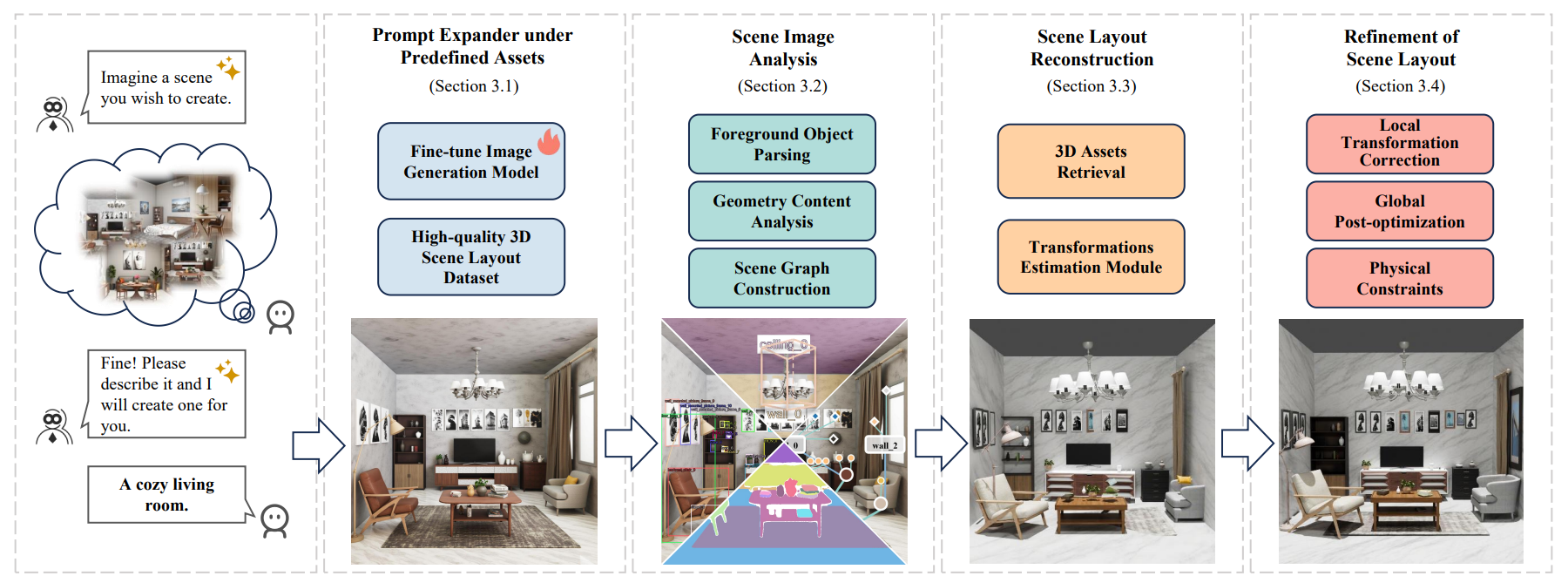
图2.文本-3D场景生成技术方法概述
研究团队使用图像生成模型Flux将用户的输入提示扩展为引导图像,通过高质量3D场景布局数据进行微调,Flux能够生成质量更高且与资产集合风格更一致的图像,这显著提高了摆放系统的可控性;接着构建一个基于预训练视觉模型的图像分析模块,融合视觉语义分割、单图像几何解析以及基于图的场景图逻辑构建功能;随后根据语义特征匹配策略,从资产集合中检索出与引导图像最匹配的对象,结合视觉语义特征、几何信息和场景布局逻辑,迭代计算每个前景对象的旋转、平移和缩放变换。最终,团队通过场景图逻辑和图像语义解析对三维场景布局进行一致性优化,确保最终3D场景在视觉和逻辑上与引导图像相近。
3D资产由自主开发的模型、高质量的开源内容及授权市场资产组合而成,并由20名具有三年以上经验的专业艺术家将这些项目布置成互动媒体级别的3D场景。
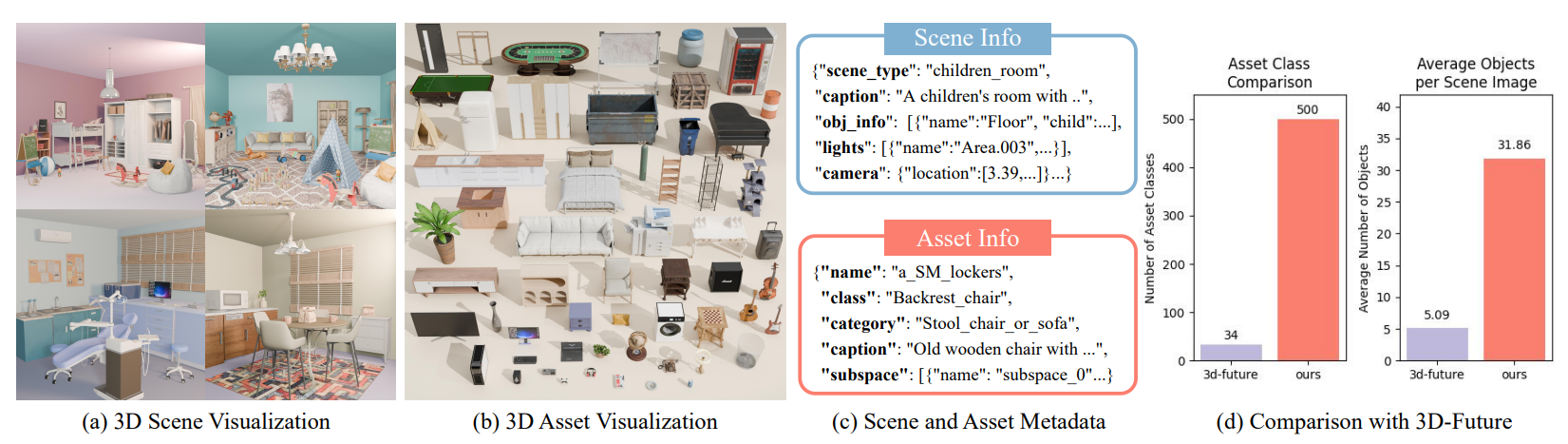
图3.3D资产及布局数据集
图像生成模型擅长生成美观且细致的二维布局,该研究方法可将这些能力应用于三维场景布局任务。与之前依赖复合资产的方法不同,团队根据引导图像以不同的姿态和位置放置资产,避免了冗余,增加了多样性。此外,团队引入了资产内部布局功能,使资产可在其他资产内进行排列,以优化空间使用并提高场景真实性。这些功能使得生成的三维场景布局更加自然、详细和具备视觉吸引力。实验结果显示,与以往的方法相比,3D场景布局质量显著提升。
实验结果显示,团队研究生成的3D场景布局在丰富度和美术质量方面优于其他先进方法。这一成果使原本需要专业美术师耗费2.5小时完成的工作流程实现了自动化,有望将所需时间降低至4分钟以内。

图4.3D场景布局方法的生成结果对比
研究成果以“Imaginarium:视觉引导的高质量3D场景布局生成”(Imaginarium: Vision-guided High-Quality 3D Scene Layout Generation)为题,被计算机图形学领域顶会SIGGRAPH Asia 2025接收,并于12月4日发表于《美国计算机协会图形汇刊》(ACM Transactions on Graphics)。
清华大学深圳国际研究生院2022级硕士生朱晓明为论文第一作者,腾讯IEG游戏AI中心高级研究员邓治博士和深圳国际研究生院副教授曾龙为论文通讯作者。研究得到国家重点研发计划“工业软件”专项课题和国家自然科学基金面上项目的资助。
论文链接:
https://dl.acm.org/doi/10.1145/3763353
供稿:深圳国际研究生院
编辑:李华山
审核:郭玲